Introduction
„Alpha Omega” is one of the leading developers of joint hardware-software solutions for neuroscience and neurosurgery. It provides deep brain stimulation systems for use in hospitals, as well as for scientific research.
For clinical neurosurgery, e. g. for neutralizing tremor caused by Parkinson’s disease, five electrodes are enough, and the BenGun electrode holder provides only 5 placeholders for the electrodes. Actually, neurosurgeons rarely use more than two electrodes. However, research purposes require many more electrodes, hundreds or even thousands.
Here „electrode” means „point of connection between the brain tissue and electric contact pad which is capable of reading electric signals or probably stimulating neurons with electric current”, as one thin pointy needle which is inserted into the brain is also called „electrode”, but may contain tens of these contact pads. For example, electrodes sold by „Dixi Medical” have 4-16 contacts, and each of these pads would be recognized as a separate electrode by the „Alpha Omega” software. Data received from each of these contact pads is called „channel”.
Previously, the scientific research systems provided by „Alpha Omega” were limited to 128 channels, that is, it could serve at most 128 electric pads that are in contact with the brain tissue. This number is clearly not enough for modern applications. Therefore I was assigned the task of increasing the number of channels.
These systems were using Gigabit Ethernet interface for transferring data into the neurophysiologist’s computer, and the resources of the DSP (TI TMS320C6678) used in the systems were quite limited, therefore the maximum available number of channels was about 560 (512 data channels + some channels that are used for service data). My colleague Firas Taha and I, with help from product manager George Tamer, succeeded to increase the number of supported channels from 128 to 512, reaching the maximum possible channels on current hardware. For increasing the number of channels even more, another approach was required.
The new approach
The solution that I proposed was quite unusual. The DSP receives data from FPGA chip (Microsemi Polarfire) via a PCIe link. Let’s connect the FPGA directly to the neurophysiologist’s computer using PCIe over Thunderbolt. Then, let’s stream the data from FPGA into the computer’s memory, and create a realtime thread that would read this data, reorder it, add the required headers and provide it to the main program, which, in turn, will use the Nvidia GPU via CUDA API in order to perform signal filtering, denoising, and the filtered data would be processed as if it were arriving from the DSP. The data will be transferred over the Thunderbolt link by FPGA, because its DMA controller was not in use and for sure will be available whenever needed.
Our FPGA team has reconfigured the Microsemi Polarfire to serve as a PCIe endpoint instead of being the Root Complex. Being endpoint doesn’t prevent it from initiating data transfers through DMA into the host computer. Now it was my turn to write a device driver for this FPGA which became a new PCIe device connected to Windows.
First problem was the huge amount of data that would be received. The new system would obtain samples from 1024 electric pads submerged into the brain tissue, plus circa 60 channels used for transferring telemetry and service information. At 40000 samples per second, with each sample being 32 bits, that would require 1084 × 32 bits × 40000 samples per second / 8 × 10242 ≈ 165.38 MiBytes per second. The FPGA has very small free memory (8867840 bits), and its cyclic buffer could hold data from only 6.39 last msecs. Additionally, the connection should be very reliable; if we were guaranteeing 99.9999 % of data arriving successfully, we would be losing 43 samples of unfiltered data every second, which is unacceptable, considering that an experiment can last for days.
However, Windows is not a realtime operating system. The smallest chunk of time that Windows works with is millisecond, which is much more than the cycle of gathering data by FPGA (200 μsec). Usually any operation in Windows takes more time; for example, thread context switch takes at least 7 msecs, and usually 9 msecs. The durations of OS operations are not limited. There could be collisions on access to memory controller, and data arriving from PCIe would wait for it to be available. Any thread in Windows can be preempted and stall in the “ready” queue for uncertain time. A thread can be transferred from one core to another, which requires dumping its descriptor block into intercore cache and loading it from the cache on the target core. These delays may cause data loss. All these hiccups should be avoided, if I were going to supply a reliable system.
In short, I had to transform Windows into realtime OS.
Connecting the FPGA device to the host computer
I decided to eliminate problems one by one.
Let’s hide a portion of memory from Windows, so it would not be able to access it. If it can’t access the memory, there will be no collisions on memory controller, and the FPGA always will be able to write data. Let’s divide this „hidden” memory into areas, and the FPGA will write each portion of gathered samples into a new area, — this technique is known as multiple buffering. Every buffer will have „ready” flag, which is set by the FPGA during write and reset by the reader during read operation, therefore the reader would always know whether the next buffer is ready for reading. The reader will check the value of the flag by polling, since we want to avoid interrupts as much as possible. By setting the „ready” flag at the very end of each buffer and by specifying „write before read” in the DMA settings at the FPGA side I guarantee that there will no be unnecessary delay between the write and read operations in case of race condition between writing the very last portion of the buffer and reading the „ready” flag. The offsets of each of the buffers from the beginning of the „hidden” memory area are predefined and known both to FPGA and to the reader thread; the length of buffer was set to be big enough for maximum available number of channels, therefore the offset of the „ready” flag is also known in advance.
Additionally, by hiding the memory from Windows and allowing access to it to only two agents, „producer” and „consumer”, — or, in my case, the FPGA and the „reader” thread, — I can omit all the synchronization issues. There will be no mutexes and no semaphores, which is good, because getting a mutex in Windows can easily take 7 msecs, — and we don’t have so much time.
I used the command bcdedit /set removememory Х in order to cut off the last X megabytes of RAM from Windows and make them inaccessible for both the OS and for programs running under it.
The usual means of accessing the memory now will not be available, yet the reader needs to somehow transfer the data (with correct headers and timestamps) into the main program for filtering and analysis. How do I do it? Well, let’s look at the Registry key HKEY_LOCAL_MACHINE\HARDWARE\RESOURCEMAP\System Resources\Physical Memory\.Translated. It has the list of physical memory mapping on the host PC. Then, by double-clicking .Translated, selecting the relevant resource and double-clicking it, the user can view the list of all memory address ranges. The base physical address of the cut-off block is calculated as the highest base address plus length of the relevant address space. Of course, since the user can access it via Regedit, a program can access it as well, though it should run with Administrator permissions. But elevating permissions is not a big deal.
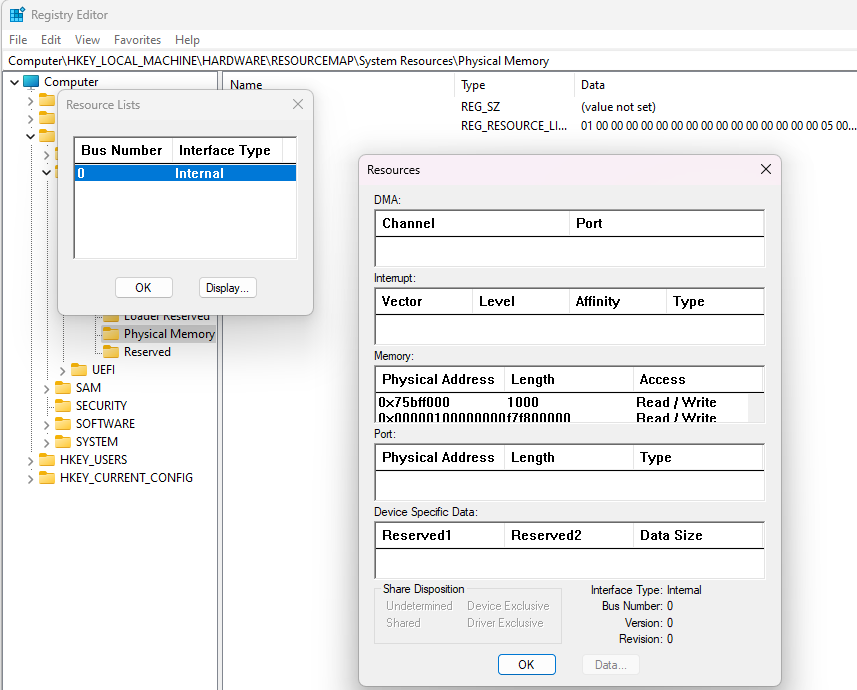
Transferring this address to FPGA is also easy. Since the device is connected by PCIe and recognized by Windows, its memory is mapped to some area in the host computer’s memory, and I find the relevant address. Since FGPA team and I have agreed on the relevant offset, I can write the starting address of cut-off section of Windows memory to FPGA.
Transferring this address to FPGA is also easy. Since the device is connected by PCIe and recognized by Windows, its memory is mapped to some area in the host computer’s memory, and I find the relevant address. Since FGPA team and I have agreed on the relevant offset, I can write the starting address of cut-off section of Windows memory to FPGA.
From this point onwards, the host computer can manage the FPGA device by setting and resetting flags in the exposed area of FPGA’s memory. The host can ask FPGA to start or stop data transfer, request a reboot, check and reset error messages and flags, and so on.
Creating the reader thread for the incoming data
Now let’s deal with the reader that will transfer the data into the main program.
The thread that will access this data will run on a dedicated core. Therefore I update its affinity:
/*
* The ID of the reader CPU core, starting from 0.
* In this example the reader runs on the 4th core, but it’s easy
* to get the total number of cores with GetSystemInfo(&sysInfo)
* and run the reader on the last core.
*/
static constexpr USHORT DRIVER_CPU_ID = 3;
. . . .
// Set the thread to run on specific core
KAFFINITY affinity = 1ULL << (DRIVER_CPU_ID);
KeSetSystemAffinityThread(affinity);Additionally, I rise its priority, but not to the maximal, since Windows is paranoid about the threads that constantly run on maximal priority. Some system functions don’t work for these threads, and critical system tasks will not run, therefore the whole system may become unstable.
/*
* Set the thread priority to the highest available -1.
* Тhe “-1” is because a thread running for a long time in HIGH_PRIORITY
* “starves” important system tasks which also run in HIGH_PRIORTY.
*/
KeSetPriorityThread(PsGetCurrentThread(), HIGH_PRIORITY – 1);However, this is not enough. Not only my thread should run on a dedicated core, but also it should not be preempted. I achieve this by setting the priority of interrupts that can preempt my thread (KIRQL) to DISPATCH_LEVEL:
KIRQL oldIrql;
KeRaiseIrql(DISPATCH_LEVEL, &oldIrql);But Windows is very suspicious towards processes that constantly run at the level that prevents interrupts. It can even kill such process. Therefore I lower the priority of allowed interrupts for a split of second and immediately rise it back. That’s enough to keep Windows calm:
/*
* It’s important that we don’t stay at DISPATCH_LEVEL for too long
* so we record the last tick we were at passive, and every once in
* a while lower the KIRQL
*/
static constexpr ULONG64 MS_ALLOWED = 50;
LARGE_INTEGER freq{};
LONGLONG lastPassiveTick = 0;
. . . .
KeQueryPerformanceCounter(&freq);
timePassed = ((KeQueryPerformanceCounter(nullptr).QuadPart – lastPassiveTick) * 1000ULL) / freq.QuadPart;
if (timePassed >= MS_ALLOWED) {
yieldProcessor();
lastTickAtPassive = KeQueryPerformanceCounter(nullptr).QuadPart;
}
/*
* Yield Processor means lowering to PASSIVE_LEVEL and then raising back
* to DISPATCH_LEVEL. It allows other important tasks to run in between,
* if they are fast enough.
*/
void yieldProcessor() {
KIRQL oldIrql;
KeLowerIrql(PASSIVE_LEVEL);
KeRaiseIrql(DISPATCH_LEVEL, &oldIrql);
}But the party is just getting started!
When my program is initialized, I’m passing over all processes that are currently running in Windows and change their affinity in order to prevent them from arriving to the core where my thread is going to run:
namespace accelerator {
class IAccelerator {
public:
explicit IAccelerator() = default;
virtual void revert() = 0;
virtual void accelerate() = 0;
virtual ~IAccelerator() = default;
};
}
namespace accelerator {
const std::vector<std::wstring> DEFAULT_BLACKLIST_PROCESSES = {
L"system",
L"system.exe",
L"winlogon.exe"
};
class AffinitySetter : public IAccelerator {
public:
/**
* Sets the processor affinity of all processes.
*
* Affinity is reset upon reseting the computer.
*
* @param activeCpuIdentifiers The cpu identifiers which should NOT be used by any process.
* @param blacklistProcesses A list of processes that should not be altered.
*
*/
explicit AffinitySetter(std::vector<uint8_t> activeCpuIdentifiers,
std::vector<std::wstring> blacklistProcesses = DEFAULT_BLACKLIST_PROCESSES);
virtual void revert();
virtual void accelerate();
virtual ~AffinitySetter() = default;
private:
ULONG_PTR getAffinityMaskWithoutBlackList(ULONG_PTR maskLimit);
std::vector<uint8_t> m_activeCpuIdentifiers;
std::vector<std::wstring> m_blacklistProcesses;
};
}
. . . . . . .
std::vector<std::unique_ptr<accelerator::IAccelerator>> accelerators;
auto affinitySetter = std::make_unique<accelerator::AffinitySetter>(
std::vector<uint8_t>({ DRIVER_CPU_ID }));
accelerators.push_back(std::move(affinitySetter));
for (auto& accelerator : accelerators) {
accelerator->accelerate();
}But even that is not enough. In addition to all previous actions, I have to be sure that none of the processes or threads that will be created in the future will not run on the dedicated core chosen for the „reader”. For that I register two callbacks, which are called after creating any new process or thread, and in these callbacks I adjust their affinity:
/*
* We want to keep this core to ourself, so register a callback for each
* process and thread created. At this callback we change their affinity
* (the core they can run on) to be different from our core
*/
if (!NT_SUCCESS(PsSetCreateProcessNotifyRoutine(newProcessCreated, FALSE))) {
DEBUG_TRACE("PsCreateProcessNotifyRoutine failed");
COMPLETE_IRP(Irp, STATUS_UNSUCCESSFUL);
}
FINALLY([&guardActivator]() {
if (guardActivator) {
PsSetCreateProcessNotifyRoutine(newProcessCreated, TRUE);
}
});
if (!NT_SUCCESS(PsSetCreateThreadNotifyRoutine(newThreadCreated))) {
DEBUG_TRACE("PsCreateProcessNotifyRoutine failed");
COMPLETE_IRP(Irp, STATUS_UNSUCCESSFUL);
}
FINALLY([&guardActivator]() {
if (guardActivator) {
PsRemoveCreateThreadNotifyRoutine(newThreadCreated);
}
});
. . . . . .
void newProcessCreated(
HANDLE ParentId,
HANDLE ProcessId,
BOOLEAN Create
)
{
UNREFERENCED_PARAMETER(ParentId);
if (Create) {
KAFFINITY affinity = ~((1ULL << (DRIVER_CPU_ID)));
KAFFINITY maximumAffinity = KeQueryActiveProcessors();
affinity &= maximumAffinity;
// Get process handle by id
HANDLE processHandle;
OBJECT_ATTRIBUTES objectAttributes{ 0 };
InitializeObjectAttributes(&objectAttributes, NULL, OBJ_KERNEL_HANDLE, NULL, NULL);
CLIENT_ID clientid{ 0 };
clientid.UniqueProcess = ProcessId;
auto status = ZwOpenProcess(&processHandle, GENERIC_ALL, &objectAttributes, &clientid);
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwOpenProcess failed getting process for pid %d with status %d", ProcessId, status);
return;
}
FINALLY([&processHandle]() {
ZwClose(processHandle);
});
// Set the process affinity by handle
DEBUG_TRACE("Will set process affinity: %d for process: %d", affinity, ProcessId);
if (affinity) {
status = ZwSetInformationProcess(processHandle, ProcessAffinityMask, &affinity, sizeof(affinity));
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwSetInformationProcess failed getting process affinity for pid %d with status %d", ProcessId, status);
return;
}
}
}
}
void newThreadCreated(
HANDLE ProcessId,
HANDLE ThreadId,
BOOLEAN Create
)
{
if (Create) {
// Thread affinity should eventually be all cpus except our own.
KAFFINITY affinity = ~((1ULL << (DRIVER_CPU_ID)));
KAFFINITY maximumAffinity = KeQueryActiveProcessors();
affinity &= maximumAffinity;
// Get process handle by id
HANDLE processHandle;
OBJECT_ATTRIBUTES objectAttributes{ 0 };
InitializeObjectAttributes(&objectAttributes, NULL, OBJ_KERNEL_HANDLE, NULL, NULL);
CLIENT_ID clientid{ 0 };
clientid.UniqueProcess = ProcessId;
auto status = ZwOpenProcess(&processHandle, GENERIC_READ, &objectAttributes, &clientid);
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwOpenProcess failed getting process for pid %d with status %d", ProcessId, status);
return;
}
FINALLY([&processHandle]() {
ZwClose(processHandle);
});
// Get the process affinity by handle
PROCESS_BASIC_INFORMATION processInformation;
ULONG returnLength;
status = ZwQueryInformationProcess(processHandle, ProcessBasicInformation, &processInformation, sizeof(processInformation), &returnLength);
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwQueryInformationProcess failed getting process for pid %d with status %d", ProcessId, status);
return;
}
// Reduce affinity to by subset of process
affinity &= processInformation.AffinityMask;
// Get thread handle by id
HANDLE threadHandle;
objectAttributes = { 0 };
InitializeObjectAttributes(&objectAttributes, NULL, OBJ_KERNEL_HANDLE, NULL, NULL);
clientid = { 0 };
clientid.UniqueThread = ThreadId;
status = ZwOpenThread(&threadHandle, GENERIC_ALL, &objectAttributes, &clientid);
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwOpenThread failed getting thread for tid %d with status %d", ProcessId, status);
return;
}
FINALLY([&threadHandle]() {
ZwClose(threadHandle);
});
// Set the thread affinity by handle
DEBUG_TRACE("Will set thread affinity: %d for thread: %d", affinity, ThreadId);
if (affinity) {
status = ZwSetInformationThread(threadHandle, ThreadAffinityMask, &affinity, sizeof(affinity));
if (!NT_SUCCESS(status)) {
DEBUG_TRACE("ZwSetInformationThread failed getting thread affinity for tid %d with status %d", ProcessId, status);
return;
}
}
}
}
Of course, at shutdown of the „reader” application I have to pass again over all processes and threads and adjust their affinity once again, allowing them to run on the core that was previously reserved for the „reader” thread. Besides, it's important to unregister these callbacks, otherwise the load on the cores will be unbalanced.
Conclusion
The „reader” thread that I've created succeeded to copy all data from the DMA target area, order it, add appropriate headers to every channel's data, check error conditions etc., and supply the data to the main application in no more then 155 μsec. Each portion of the data was processed in less than the hard-realtime cycle of the FPGA board, and the thread was even caught spending some time on polling the next „ready” flag.
In other words, I've implemented a kind of realtime task that runs under Windows. The used technique is very similar to what commercial solutions, like RTX64 or On Time, provide: they hide some hardware from Windows and use it for their own purposes. However, there are some differences:
Let's compare my solution to RTX64 and On Time commercial alternatives:
- In both „RTX64” and „On Time” the interaction between Windows and the real-time operating system that run on the dedicated hardware is limited, while in my case the user can use every interprocess communication available in Windows. (I used managed shared memory segments provided by Boost 1.81 in order to transfer ordered data from the „reader” thread into the main program).
- The programs for „RTX64” and „On Time” have to be compiled using a dedicated SDK. In my case, Microsoft Visual Studio is enough.
- In both „RTX64” and „On Time” solutions the code running under Windows has very few possibilities to affect the code running under the realtime OS. For example, it's impossible, or at least very difficult to change the program that is executed inside the realtime OS on-the-fly; usually it requires updating the image and restarting the OS. (Or at least I didn't find a simple way to do it, — well, that's also a possibility 😉). In my solution, the realtime code is just a Windows process or thread, it can be freely modified or replaced with another as required. In fact, I used the trick of replacing the „reader's” code for error recovery.
- Let's not forget the commercial aspect. Each developer's seat for „RTX64” costs about US$ 10000; besides, every user's license (e.g. the system bought by a neurophysiologist for research purposes) costs also US$ 500. My solution does not add any costs to the price of the system.
Microsoft does not recommend using bcdedit /set removememory Х for any purposes except for emulating systems with low amount of RAM. Microsoft does not guarantee that the cut off region will be located at the end of the memory space, or that it will be contiguous. However, this solution is recommended by „WinDriver” for similar task of DMA transfer from an external device into the host computer that runs under Windows. Anyway, there is also truncatememory 0xХ option that receives an explicit address of the inaccessible region as the parameter.
Final thoughts
I've successfully and efficiently solved the problem of implementing a realtime task under Windows, with cycle of less than 200 μsec. The task is defined as soft realtime, because theoretically there could be unavoidable interrupts that delay the work, but in all the trials and overnight runs the solution did not lose any packet of data. Even if there were hiccups, the task recovered soon enough. Besides, I succeeded to do it quickly and cost-efficiently.
Mission accomplished!